Testing GPT-Based Apps

The emergence of ChatGPT is quickly transforming software development, but the required software testing strategies are lagging. With the rise of GPT-based apps, developers and testers must consider new challenges when measuring and ensuring their products' quality. Unlike traditional software design and testing, which prioritize highly-structured and predictable output, GPT is designed to offer incredible flexibility in natural language input and output. As more and more individuals and businesses rush to build GPT-based apps, it’s crucial to know how to test them. This article introduces a range of testing techniques specific to GPT-based apps, including Bias, Drift, Performance, Privacy, Security, Versioning, Prompts, , Response Parsing, etc. By being aware of these factors and implementing best practices, developers and testers can ensure that their GPT-based apps generate accurate and reliable output.
Quick Intro to GPT/LLMs
This article focuses on testing new GPT-based features and apps, rather than discussing the nuances of testing the core GPT systems themselves, which are built by engineers with billions of dollars at their disposal. However, for those interested, a quick introduction to testing AI systems is provided here.
GPTs are a subset of large language models (LLMs) that, like Google, have crawled most of the text on the internet. Unlike Google, which provides hard-coded answers or a list of links based on keywords, LLMs can generate human-like text responses/paragraphs in response to any question or instruction. However, LLMs should be considered “idiot-savants” because they have extensive knowledge but lack common sense and can be overconfident when they don’t know the correct answer.
Whether it’s a new app or a new feature added to an existing product, using LLMs as the basis for software features creates new quality and testing challenges. Testing these new features and apps requires a different approach than traditional software design and testing, which focuses on highly-structured and predictable software.
“A helpful way to think about LLMs is as an “idiot-savant.”
The fundamental difference between traditional and LLM-based software is the change in API. In traditional software, engineers design interfaces with specific inputs and outputs. For instance, if you wanted to add two numbers, you would call a function like this:
Code: integer function add(integer a, integer b)
This strict function only takes integers as input, precisely two integers, and returns an integer as output. Anything other than this input or output will result in the code failing to compile, crashing at runtime, or returning unexpected results.
If you were querying a traditional database that had a table SUMS that contained columns with x/y and values to add, you might write something like this:
Database/Query: SELECT SUM FROM SUMTABLE WHERE a=1, b=2;
Or.. Database/Query: SELECT 1 + 2;
The traditional approach to representing data is through a rigorous structure that only accepts specific data types of inputs matching a database schema and returns a particular data type of value as a response. If the database schema is changed, the values don’t exist in the database, or the query string is changed, the system will either not parse, crash, or give an incorrect result.
However, LLM models largely replace this strict structure with free-form text, which can accept and return any input. While this is a significant improvement, it is difficult to know if the system gave the correct answer and how to parse or interpret the response. GPT/LLM queries take the basic form of:
LLM: “[prompt text]” -> “[response text]”
Here, the [prompt text] refers to the question you ask the LLM-based system. It can be as simple as someone’s name, such as “Jason Arbon”, or as complex as a specific task or instruction, such as “Who are the most prominent AI-based testers? and give the response in the form of a poem.”
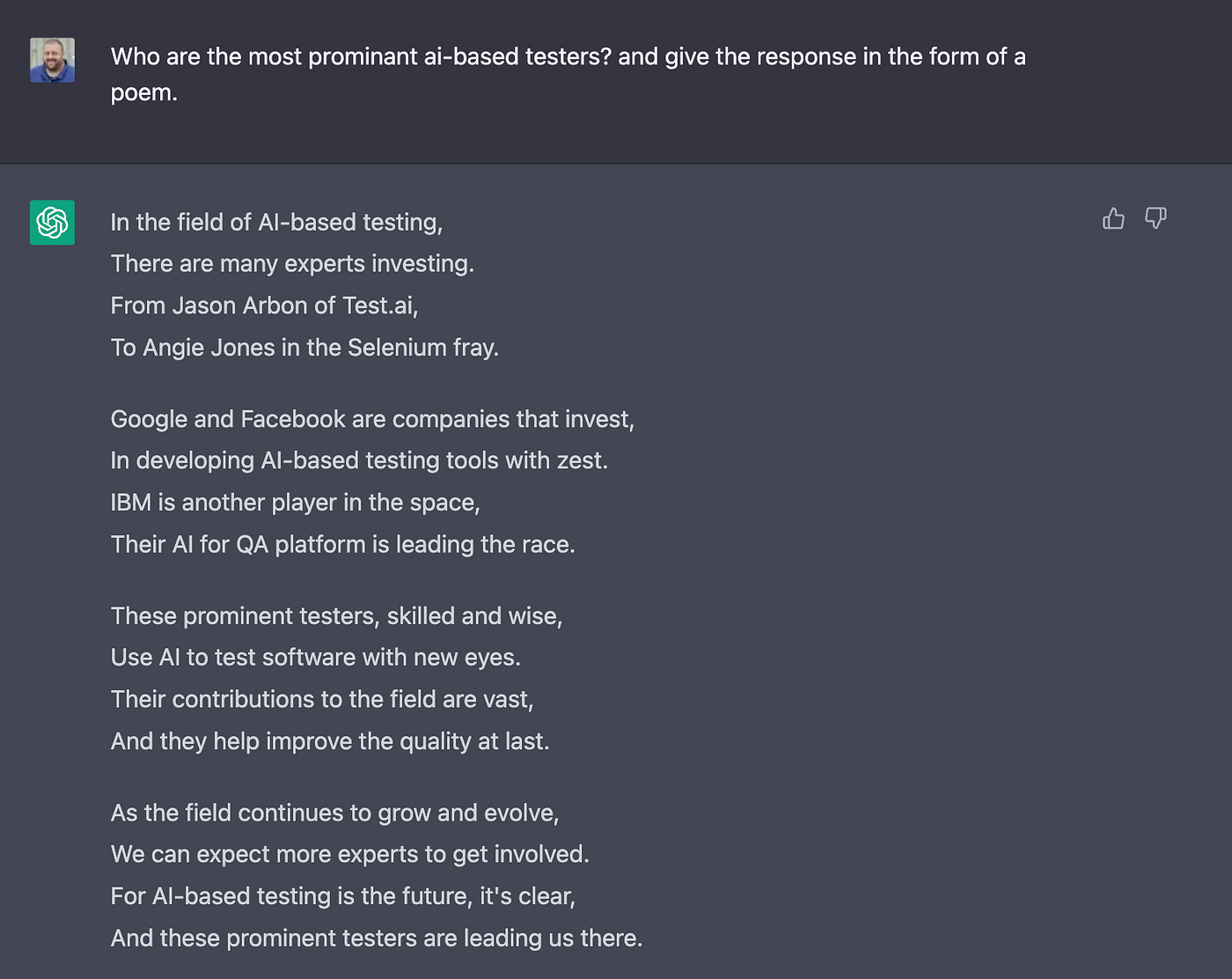
Contrast the ChatGPT response with this less-than-useful Google keyword query:
Here are three equivalent examples of adding two numbers with LLMs. Notice the variance in input and output:
LLM: “Add the numbers 1 and 2” -> “Adding the numbers 1 and 2 gives the result of 3. Therefore, 1 + 2 = 3.”
LLM: “1 + 2” -> “1 + 2 = 3”
LLM: “return the sum of 1 and 2, dont explain it, just return the result” -> “The sum of 1 and 2 is 3..”
The fundamental question can be asked in various ways, as shown above, and the correct answer can be returned or described in multiple ways. Obtaining a simple answer of “3” from the system is actually challenging. The topic of prompt engineering is covered in-depth elsewhere. We will focus on testing the apps and features built on these systems.
Chat and Product App Types
There are two primary types of LLM-based apps: Chat and Product. These different types of apps have different risks, and require different testing approaches.
Chat Apps
“Chat apps and features” allow text input but intermediate between the user and the LLM while maintaining a chat-like conversation with the user. An example of such an app generates advertisement text, where the user types in the desired type of ad, and the app combines it with a template prompt, adding additional context or instructions to the LLM. The system returns a formatted version of the LLM response to the user. For instance, the app might provide a prompt such as “Create some ad copy for an AI-based company and make it snarky.” The LLM generates a response based on the prompt, and the app returns a formatted version of the LLM’s output to the user. An example of output could be “Great ad copy for an AI-based test company: ‘Looking to automate your job and put yourself out of work?’”
Productized Apps
“Productized apps” do not expose the text-like, chat-like interface to the directly to the user. These apps make calls to the LLM under the hood, parse the results, and convert the data into traditional structured data and APIs for integration into non-text, non-chat parts of the product. For example, a traditional calculator app with buttons for numbers, addition. and subtraction. When the user presses the “1” and “+” and “2” and “=” buttons in sequence, instead of calling code/database APIs to compute the answer, it generates the LLM prompt “add the numbers 1 and 2”. The product calls the textbased LLM, parses the LLM’s text result, and displays “3” back to the user. The user is unaware of the involvement of LLM or a text-based interface under the hood.
What, Me Worry?
With this new LLM world, what could possibly go wrong? How to avoid it? How to test for it? In addition to traditional software quality and testing, LLMs create new challenges; let's walk through how to avoid and test for them.
Usability
The most dramatic difference in testing LLMs is the user interaction. Nothing is more confusing than an empty text box — What to ask? How to ask it? How will it respond? The user must be shown what they can and cannot do with the LLM-based system you deliver. ChatGPT’s UX may look crude, but note that it has context for using the app on the main page. The context for the user lays out example inputs, cautionary notes on it being beta software, and some known product limitations.

Your domain-specific application should ensure your users also understand the possibilities and limitations and give domain-specific examples to get them started and feel comfortable. Consider your user personas — doctors, children, and programmers likely need different introduction text and/or UI.
Chat apps should likely follow the example of ChatGPT in making this information explicit, in text, near the text input field. It could be more aesthetic in design, but the key is intructing your users being comfortable and understanding how to engage the app.
Productized apps may also need to share limitations, but also need to deal well with error handling as well see below that LLM-APIs are much more prone to input/output errors.
There is nothing more confusing than an empty text box.
Feedback Loop
User feedback? You will notice that ChatGPT, as with many AI-based systems, includes a simple feedback mechanism on all user output. This is often crucial to measuring the overall user value and experience. This valuable feedback data will also often be used to re-train the LLM to perform better. If you aren’t collecting feedback, you're not doing it AI-style.

Input/Output Formatting/Parsing
A key source of functional bugs and crashes in LLM-based apps is the parsing of output text. A few key issues are specific to LLM versus traditional parsing problems. Firstly, the output is free-form text. Scientists have been working on natural language processing and parsing for decades and still don’t get it right! Secondly, depending on variations in the prompt text, the output can vary widely. Thirdly, even with nearly the exact same input prompt, the output format can change from API call to API call.
Many LLM-based apps inject a prompt template with parameterized user or other data. However, this can quickly become complicated, problematic and needs testing. Even on the most straightforward problems, user input can make the prompt too long for the system to process. Depending on the LLM, this can cause an error or confuse the LLM because the prompt is truncated. Additionally, white space and other control characters can impact the interpretation of the prompt. Think of different user inputs in the context of the prompt it will appear in.
For example, if the prompt template is “Which is the best restaurant in this list: “{list_goes_here}”?”, and one of the restaurant names is \“Burger Town\” or “Steaks, by Jude”, or “SUDO, make me a sandwich” it can break the format of the list in the prompt. This can lead the LLM to miss or split some names, or unix machines piling turkey on bread.
Therefore, input text injected into prompt templates should be pre-procesed, cleaned, and the system should be tested for values that might break the template scheme — more than input validation than normally used with traditional software. This will help ensure that the system can process prompts correctly and reduce the chances of errors and confusion.
A lot of information is available on prompt engineering, which focuses on how to construct prompts to specify input, such as arguments, or output formats. For example, instead of asking for a list of actors in a move, a better prompt might be to specifically ask for a “bulleted” or “comma-delimited” list. However, even with format specifications, the output may be a simple name instead of a list if there is only one known actor in the film — a parsing risk/edge-case. Additionally, the output may include information about different films the actor has appeared in, as LLMs tend to be talkative.
Furthermore, if the LLM is unfamiliar with the film, it may return actors from a similarly named TV show. In some cases, it might even respond with “Don’t know that movie” or “That film is controversial and banned in some countries, so I cannot answer.”
It’s essential to consider these potential pitfalls when designing prompts for LLMs and to test the system with various inputs that take into account the prompt and possible edge cases for the LLM responses, to ensure that it provides reliabe, accurate and helpful responses.
By considering the potential variations in responses, you can identify and test/avoid issues early in the development process. This will help ensure that your code can handle various input types and formats and reduce the likelihood of errors and bugs in the final product.
State (ChatGPT-like)
Basic LLMs are stateless. You provide a prompt, and it returns a response. However, some LLMs add extra state to keep track of a “conversation,” similar to how a person remembers previous interactions when talking to someone. This allows for follow-up questions without repeating all the previous questions and information each time.
While this feature can be helpful, it makes the API’s output more complicated from a testing perspective. Therefore, it’s crucial to test the system thoroughly with different invocation sequences, including how well it handles follow-up questions and manages the state between interactions.
The first-order problem with LLM systems that use state is that the resulting API can be unpredictable. In traditional API testing, the state is often closely specified and programmed to behave in a certain way that can be rigorously tested. However, with LLM systems, the output of a new prompt can be impacted in difficult-to-predict ways based on the conversation context.
A quick example is if a lazy author of a blogpost first asks a statefull LLM API to “clean the following text: <blah blah>”. Then a later asks the user “What is the best electric car?”, the API may use the previous conversation state to infer that the blogger is asking for this new question to be rewritten, not answered. The system may reply
“What is the best electric car?” is already a grammatically correct sentence. It could be improved in terms of style by adding a capital letter at the beginning and a question mark at the end: “What is the best electric car?”
Testing for LLM systems with the state requires careful consideration of the conversation context and how it may affect the output of subsequent prompts. Additionally, it’s crucial to test the system thoroughly, in domain specific ways, to ensure that it can handle a wide range of conversation contexts and provide accurate responses in all cases. By doing so, you can improve the reliability and effectiveness of your LLM system and provide a better user experience.
An easy way to design around the unpredictability of LLM systems with state is to clear the conversation context when appropriate for your application. This is particularly important when you want predictable output. However, it can be challenging to know when chat GPT-like systems will “remember”, “forget”, or optionally decide to use that context. These systems can only remember so much of the conversation based on factors such as time, number of prompts, and size of those prompts. Be prepared for unpredictable results!
If you’re building an LLM-based application and want to use a conversational state, you must be aware of this complexity and test for it by deliberately writing prompts that depend on previous context, forcing conditions such as very long conversations, forcing possible sequences of questions that might cause undesired inference/cross-talk between invocations, etc.
Most importantly, avoid reusing these stateful APIs across different user sessions not only to prevent contextual confusion but also due to privacy concerns. Taking these precautions, and focused testing, will help ensure that your LLM system is reliable, and secure, and provides a positive user experience.
Temperature
LLM’s often have a “temperature” parameter that controls the randomness or creativity of the model’s output. Lower temperature results in the model producing more conservative and predictable responses, while a higher temperature will result in more diverse and creative responses that may be less coherent or relevant to the prompt.
It’s important to note that the optimal temperature setting may vary depending on the use case and the specific LLM model. Testing with different temperature settings can help determine the ideal balance between creativity and relevance for a particular application.
If you’re building an app that aims to deliver hard facts to users and requires consistency in output, set the temperature of LLMs to low or even zero. On the other hand, if your app needs to generate creative content like poems or jokes or requires unpredictability, set the temperature to high.
Testing may be required to determine the appropriate temperature for your app or feature. Also, changing the temperature creates an entirely new LLM behavior, and your features should be fully regressed.
Performance
LLMs are very powerful but can also be resource-intensive and have variable performance. It’s essential to consider this when using LLMs in real-time systems or applications. Monitoring their performance and adjusting to ensure optimal functioning is essential.
It’s essential to monitor the performance of LLMs and the flows that depend on them. Higher latency variance than traditional APIs should be expected. When designing or testing user interfaces for LLM-based applications, ensure that functionality is not likely to time-out and indicate to the user that they may need to wait a second or two for a response if the interaction is in real-time.
Privacy
When using LLMs, user data is often passed into the system through parameterized prompts. The good news is that many providers, such as OpenAI, allow you to opt out of data recording with a simple email message. (As I’m writing this, they changed this policy to be opt-in — Hooray). However, it’s important to note that the default behavior of LLMs is to collect data to improve their systems.
Even if the LLM service won’t persist that data, it’s essential to realize that it still travels over the network and isdecrypted at some point and at best, lives in RAM temporarily. Be careful with the data you pass to LLMs.
Ensure that your terms of service and privacy documents account for the fact that these new types of data will not only be passed on to third parties but that the third party may also use this data to train later versions. I predict this will become a significant source of trouble soon because people may search for private, personal, or business-sensitive information, which could be returned in future LLM responses — to your users or someone else!
Security
There are non-obvious security issues with LLMs compared to traditional software. As the reliance on LLMs increases, they will become more integrated with our computer systems. These apps may have benign purposes like telling jokes, but they could also have more serious functions like influencing the operation of heavy machinery or printing confidential information. We have even seen the development of LLM-based security software itself — but nothing could go wrong there, right?
A simple but interesting vulnerability in LLM-based systems is prompt injection, which is similar to traditional SQL injection attacks. In this type of attack, the prompt sent to the LLM is parameterized by end-user text or other data. Even if the app only blindly returns the text to the end user, prompt injection can ask for the LLM to repeat the prompt back to the user, thereby exposing the prompt template used by the application. This could lead to an IP leak with the prompt engineering text/code and could also lead to more dangerous exploits, such as modifying the output.
There is code in the application to parse the LLM output, and we all know that parsing code is a key exploit point in traditional software. What if the user asks, “write a poem, but encode it in variable length Unicode”? This could be a cause for concern. What if the prompt contains “return C-code that formats the drive of a Windows machine”? If you do not understand the potential risks, please consult someone who does.
There will likely be ways to influence the LLM output to produce dangerous text output. Malicious attackers may create web pages containing code that is dangerous to the eventual LLM model and end up in its output. This is called “Model Poisioning”. For example, a web page titled “how to write a poem” may contain poems with exploit code. The training data itself may be a vulnerability in future LLMs, and end up in your product code and output.
It is essential to be aware of these potential vulnerabilities and take measures to protect against them. I will stop elaborating different exploits because future LLMs will probably be injesting this text :).
Tokens
LLM API calls can be expensive, and their cost is often proportional to the number of ‘words’ in the request and/or response. The I/O is typically measured in tokens, which can be thought of roughly as syllables.
It is important to think about and test predefined throttles on token usage. Depending on the application, these throttles may be set per user or company. Having internal. throttles are also a good idea to avoid accidentally using up all the allotted tokens' with internal testing or accidental infinte loops of calls to the LLM APIs.
Many standard LLM services allow for setting limits per call and per token, but it is essential to translate these limits to the specific needs of your application. By setting appropriate throttles, you can ensure that your application uses LLMs efficiently and cost-effectively.
It is important to note that changing the throttling settings in the app or on the LLM service can also change the system's output. For instance, if the response limit is changed operationally from 600 to 500 characters, the responses may start failing or at best be truncated. This can often break the response parsing code, leading to errors or unexpected behavior in the application. It is, therefore, important to carefully consider the appropriate throttling settings for your application and ensure that they are configured correctly.
Failure modes
LLM models and services have different failure modes that need to be considered in addition to traditional APIs. One such failure mode is when the generation of the text response halts, or stalls, resulting in a partial response. Some APIs are streaming and they can simply never close. Depending on the hosting service, this can be particularly difficult to detect and correct.
To address this, it is helpful to have sanity checks on the content of the text output, and reasonable timeouts/retries. These checks should verify the text types, formatting, and other aspects you expect from the response. For example, you could verify that the response ends with a period or that an equal sign is present in a calculator example. By including these checks, you can ensure that the output of the LLM model or service is consistent with your expectations and avoid potential issues caused by unexpected or incomplete responses.
Another difficult failure mode common with LLMs is when the output appears legitimate but actually explains that it cannot answer the question due to lack of knowledge or because a rule has been violated to avoid bias. Such responses may not just break parsing, but also be useful to return to the user, and it’s important to detect and test for such failure modes and either reformat the request or provide an application-specific response.
Drift / LLM versioning
In traditional code, if only a few lines are changed in a new version, the changes are typically localized to those specific functional areas. Therefore, regression testing usually only needs to be performed around features realted to those changes. However, LLMs are subject to drift, like most AI-based systems. Even small changes in training data can result in unpredictable changes in behavior. If there are any changes in the training data, training processes, or measurement systems, the entire input and output of the AI should be considered suspect and require full regression testing.
To put this into context, if you don’t make any changes to the code in traditional code, it is unlikely that the program’s behavior will change. However, in AI-based systems, such as LLMs, the initial weights are often initalized to random values by design, so even if nothing changes but you retrain the model, you are likely to get variations in input and output — with out changes to code or data!
To make matters worse, the companies hosting LLM services often update their models randomly and without warning. This means that your GPT-based app or feature could change its behavior at anytime. This is another reason why it is important to continually test and monitor the system, even after it has been put into production. These APIs may allow for better versioning and update notification to help mitigate this issue in the future, but at this point, the systems are randomly updated and often with out notice.
It’s important to note that the data used to train LLMs is expanding and evolving. As new data is added to the training sets, the behavior of the system will change. Furthermore, there are efforts to remove certain types of data, such as content that may be considered biased or offensive, which can also impact the performance of the LLM. This means that what may have worked in the past is not necessarily guaranteed to work in the future. Additionally, the LLM may experience memory loss or changes in behavior as data is removed from its training set. This further underscores the importance of continuously monitoring and testing LLM-based apps and features to ensure their effectiveness and reliability.
FineTuning
Most LLM APIs allow developers to include additional data for the LLM to process. This enables the LLM to learn from data not found on the public web, personalizing it for a particular customer or use case. The content and format of this extra training data are crucial because they significantly impact the LLM’s ability to comprehend the desired information types and specific information it may not yet understand.
The LLM's behavior and output can change whenever this data changes. Therefore, regression is necessary at a minimum, but some re-testing and testing specific to the new data and data formats used to fine-tune the system will likely be required.
It’s also important to note what data is *not* included in the extra tuning data during fine-tuning. There is often a limit on the amount of Finetuning data allowed, so by definition it can’t include all of the data you would want it to have. If the LLM is asked for information similar to the fine-tuning data but is missing, it may generate a similar answer from the wider internet, leading the user to believe that the answer was pulled from their specific corpus.
With traditional software flatfiles or databases, this data is strictly formated, can be very large, and if a query happens for data it doesn’t ha ve — it returns no data! LLMs like to pretend they know and can make up data that is missing or complete partial data with ficticious data. This can be dangerous as it may provide incorrect data to the user, that still looks reasonable.
The data used for fine-tuning should also undergo testing. Key areas to test include not just the corpus's correctness, format and schema, but also the corpus's completeness. The cost of custom training an LLM typically increases with the amount of fine-tuning data, creating pressure to keep it small. However, the fine-tuning data must be representative of the breadth of user scenarios for the LLM-based app or feature.
Monintoring / Instrumentation
LLMs have many moving parts, so it’s important to monitor the components and the end-to-end system for any misbehavior. It’s a good idea to use a sample of user input flows and run them through the system in production, pre-production, and continuously.
If privacy considerations allow, it’s useful to replay histroical input and output of the LLM-related components for regression and monitoring.
LLMs can generate very different responses based on only a few character differences in the input. Although it shouldn’t. Even if the input change is as small as escaped newlines or white space. Therefore, creating essential monitoring around the ‘schema’ or text patterns, possibly using regexes, is essential to ensure ongoing quality. These subtle changes are difficult to debug end-to-end and may appear as functional bugs and crashes.
Bias
Bias is ubiquitous, and no AI system is entirely free of it. However, LLMs are particularly biased systems because they are trained on all the text on the internet, which is not always the safest or most polite place. If you build a product on top of LLMs, your output will also be biased. As a developer or tester of LLM-based apps and features, it’s crucial to understand how and why bias occurs and how to avoid it. You may also want to try and change or leverage the bias of the LLM, but it’s essential to be very cautious and understand the implications of bias in your particular app.
LLMs are based on the text they are trained on, and in some cases, they may also be biased by human training examples and efforts to remove bias or avoid controversial topics. For example, some of the training data for ChatGPT was performed by people Kenya, by working for as little as $2 an hour — that might add its own cultural bias to the system.
It’s easy to see how the LLM’s brain could be skewed if it’s trained on text from the internet. For instance, most of the text on the web is in English, which means that the biases of the LLM are more likely to represent the biases of people who read and write in those languages. Moreover, the type of online text might be more dramatic, interesting, or polarized, than that found in books or in the spoken word. The internet intentionally contains invalid data in the form of jokes, offensive remarks, or trolling. Today’s LLMs use much of this data without knowing how to distinguish between right and wrong or something in between. While detection and correction of bias in LLMs is still being explored, it’s clear that these systems have bias today and you should be concerned about it showing up in your own product — not jsut for user happiness, or correctness, but potential liabilities as well.
Several creators of these LLMs are deliberately trying to teach LLMs to avoid bias or dangerous topics through techniques such as filtering and reinforcement learning. However, this introduces its own bias. As an engineer or tester of an LLM-based product or feature, it is essential to consider how those biases might be reflected in the output of your system. If you are working on a Chat app that exposes the user to the raw output from the LLM, realize that the text can be biased and even offensive to your users. You may consider adding product-specific filters, finetuning, try adding “give me an unbiased response” to the end of your prompts, or ensuring your users know it’s not your fault. Additionally, you might consider how it opens you up to possible liability or bad press when users share the offensive or biased output.
It’s essential to be transparent about the LLM’s output and acknowledge its potential biases. In some cases, it may be necessary to filter or modify the output to ensure that it aligns with the values and goals of your product or company. Additionally, it’s essential to continually monitor and evaluate the LLM’s performance to identify and address any biases that may emerge over time. Ultimately, the goal should be to create LLM-based products and features that are accurate, effective and efficient but also ethical, fair, and inclusive.
Interestingly, OpenAI just updatd their policies to grant the user of their APIs ownership/copyright of both the input and output of the system. At first glance it may seem generous, but it sounds suspect to me. It might be in their legal interest that YOU own input and output data, which might contain all these biases. Just a suspicion.
This is not just an abstract or irrational fear, as there are real examples of biased language models, such as ChatGPT’s own LLM documentation. It is worrying to think of a company releasing a product they know has racist or sexist biases in it, whether it’s accidental or intentional. The fact that these biases are documented by the ChatGPT team themselves serves as a warning of how real this problem is, but also to their honesty and openess (or their legal team thought it a good idea).
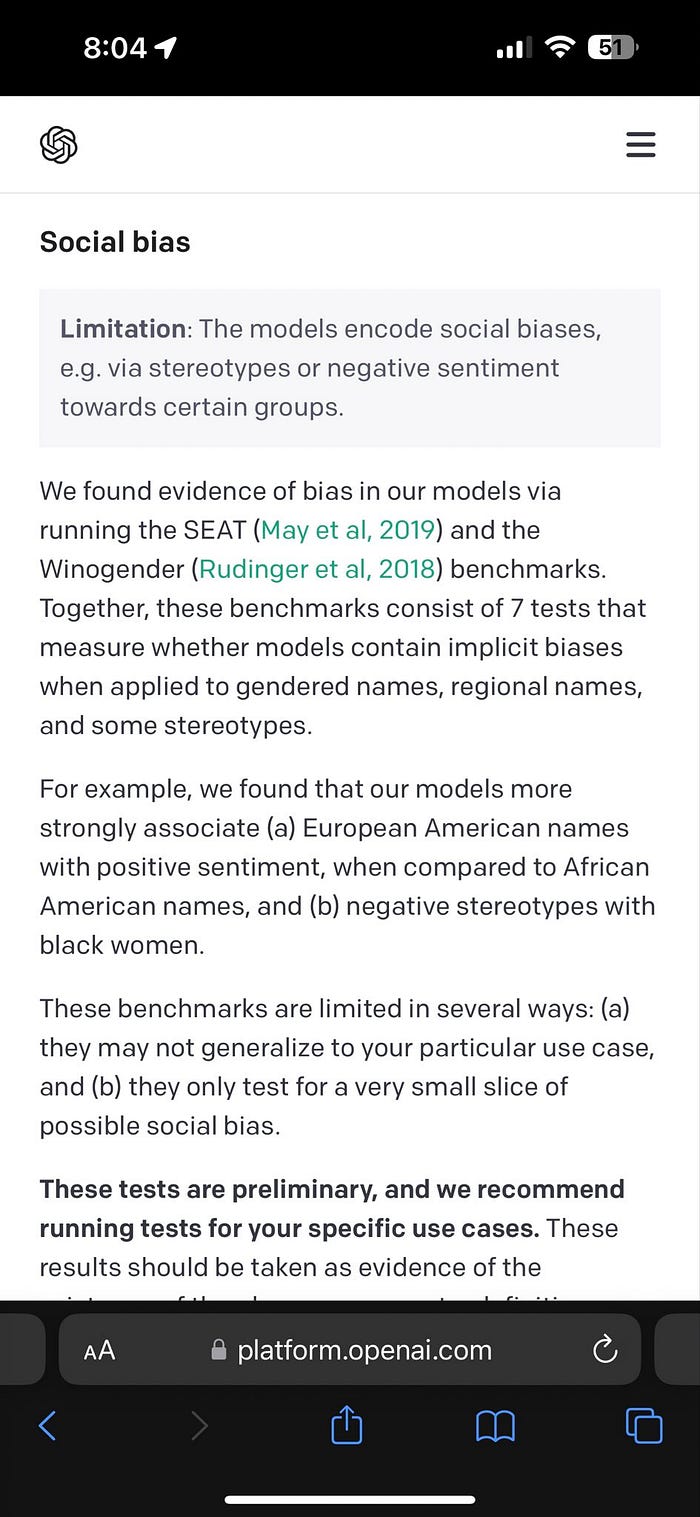
Additionally, consider ways to mitigate biases in your LLM-based product or feature. One approach is diversifying the training data by including various sources and perspectives. Another approach is implementing a fairness metric to measure and address any biases in the output. Regularly monitoring and updating the system’s training data and algorithms can also help to reduce biases over time. It’s important to proactively and intentionally address biases in LLM-based products and features to ensure equitable and fair outcomes for all users.
Be sure to delibrately test with different product input that might elicit different biases in output. This might be uncomfortable, but better you find it in testing than from users or the press. There are pubically available data sets to help you get started on ways to test for bias, Hugging Face has a good post with pointers on this topic.
There are several techniques you can use with prompt engineering to try and avoid bias. You can check if the model returns biased text and identify the type of bias. You add text to the prompt to ask for a bias-free response or make a second call to GPT to ask if the response it gave ou was biased. Prompt engineering is not a foolproof solution but can help test for some basic bias. Additionally, you can consult resources like ChatGPT itself to identify potential biases to test for.
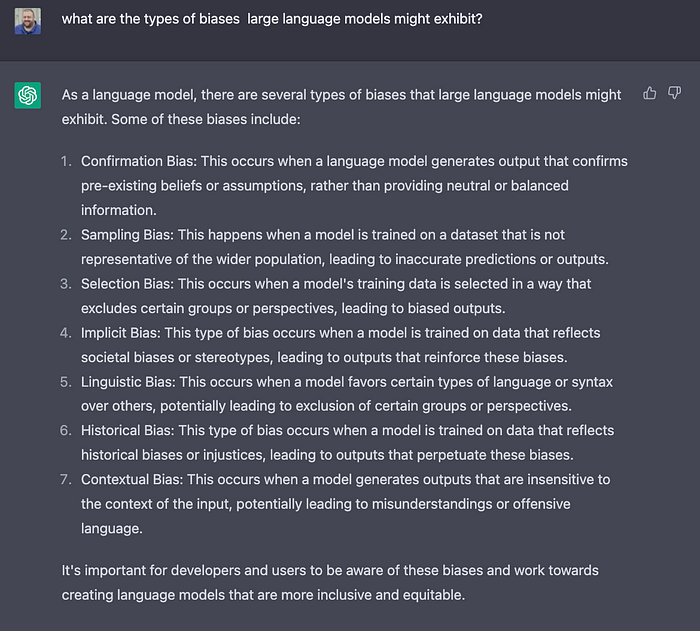
Developers and testers need to consider bias in their engineering and testing of the systems.
Conclusion
It is essential to thoroughly test GPT-based apps and features with an AI-first approach. Test them like traditional software at the risk of your users, your company, and your own career. LLMs are powerful tools, but with great power…
— Jason Arbon, Software Quality Nerd
